Are Simple Momentum Strategies Too Dumb? Introducing Probabilistic Momentum

Momentum remains the most cherished and frequently used strategy for tactical investors and quantitative systems. Empirical support for momentum as a ubiqutous anomaly across global financial markets is virtually iron-clad– supported by even the most skeptical high priests of academic finance. Simple momentum strategies seek to buy the best performers by comparing the average or compound return between two assets or a group of assets. The beauty of this approach is its inherent simplicity– from a quantitative standpoint this increases the chances that a strategy will be robust and work in the future. The downside to this approach is that it does not capture some important pieces of information that can lead to: 1) incorrect preferences 2) make the system more susceptible to random noise, and 3) also dramatically magnify trading costs.
Consider the picture of the two horses above. If we are watching a horse race and try to determine which horse is going to take the lead over some time interval (say the next 10 seconds) our simplest strategy is to pick the horse that is currently winning now. For those of you who have observed a horse race, often two horses that are close will frequently shift positions in taking the lead. Sometimes they will alternate (negatively correlated) and other times they will accelerate and slow down at the same time (correlated). Certain horses tend to be less consistent and are prone to bursts of speed followed by a more measured pace (high volatility), while others are very steady (low volatility). Depending on how the horses are paired together, it may be difficult to accurately pick which one will lead just by simple momentum alone. Intuitively, the human eye can notice that one horse will lead the other with a consistent performance- and despite shifting positions occasionally, these shifts are small and and the leading horse is clearly gaining a significant lead. Ultimately, we must acknowledge that to determine whether one horse or one stock is outperforming the other, we need to capture the relationship between the two and also their relative noise in addition to just a simple measure of distance versus time.
In terms of investing, what we really want to know is how to determine the probability or confidence that one asset is going to outperform the other. Surely if the odds of outperformance are only 51% for example, this is not much better than flipping a coin. It is unlikely that two assets are statistically different from one another in that context. But how do we determine such a probability as it relates to momentum? Suppose we have assets A and B. We want to determine the probability that A will outperform B. This implies that B will serve as an index or benchmark to A. In standard finance curriculum, we know that the Information Ratio is an easy way to capture the relative returns in relation to the risk versus some benchmark. It is calculated as:
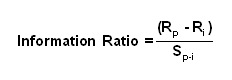
Where Rp= return on the portfolio or asset in question and
Ri= return on the index or benchmark
Sp-i= the tracking error of the portfolio versus the benchmark
The next question is how do we translate this to a probability? Typically one would use a normal distribution to find the probability using the information ratio (IR) as an input. However, the normal distribution is only appropriate with a large sample size. For smaller sample sizes that are prevalent with momentum lookbacks it is more appropriate to use a t-distribution. Thus
Probabilistic Momentum (A vs B)= Tconf (IR)
Probabilistic Momentum (B vs A)= 1-Probabilistic Momentum (A vs B)
This number for A vs B is subtracted from 1 if the information ratio is positive and kept as is if the information ratio is negative. The degrees of freedom is equal to the number of periods in the lookback minus one. In one neat calculation we have compressed the momentum measurement into a probability– one that incorporates the correlation and relative volatility of the two assets as well as their momentum. This allows us to make more intelligent momentum trades while also avoiding excessive transaction costs. The next aspect of probabilistic momentum is to make use of the concept of hysteresis. Since markets are noisy it is difficult to tell whether one asset is outperforming the other. One effective filter is to avoid switching in between two boundaries. This implies switching assets only when the confidence of one being greater than the other is greater than a certain threshold. For example, if I specify a confidence level of 60%, I will switch only when each asset has a 60% probability of being greater than the other. This leaves a buffer zone of 20% ( 2x(60%-50%)) to avoid noise in making the switch. The result is a smooth transition from one asset to the other. Lets first look at how probabilistic momentum appears versus a simple momentum scheme that uses just the relative return to make the switch between assets.

Notice that the switch between trading SPY and TLT (S&P500 and Treasurys) using probabilistic momentum are much smoother than using simple momentum. The timing of the trades also appears superior in many cases. Now lets look at a backtest of using probablistic momentum with a 60-day lookback versus a simple momentum system on both SPY and TLT with a confidence level of 60%.

As you can see, using probabilistic momentum manages to: 1) increase return 2) dramatically reduce turnover 3) increases the sharpe ratio of return to risk. This is accomplished gross of trading costs, comparisons net of a reasonable trading cost are even more compelling. From a client standpoint, there is no question that fewer trades (especially avoiding insignificant trades that fail to capture the right direction) also is highly appealing, putting aside the obvious tax implications of more frequent trading. Is this concept robust? On average across a wide range of pairs and time frames the answer is yes. For example here is a broad sample of lookbacks for SPY vs TLT:

In this example, probabilistic momentum outperforms simple momentum over virtually all lookbacks with an incredible edge of over 2% cagr. Turnover is reduced by an average of almost 70%. The sharpe ratio is on average roughly .13 higher for probabilistic versus simple. While this comparison is by no means conclusive, it shows the power of using this approach. There are a few caveats: 1) the threshold for confidence is a parameter that needs to be determined–although most work well. using larger thresholds creates greater lag and fewer trades, and vice versa and this tradeoff needs to be determined. As a guide for shorter lookbacks under 30 days a larger threshold (75% or as high as 95% works for very short time frames) is more appropriate. For longer lookbacks a confidence level between 55% and 75% tends to work better. 2) the trendier one asset is versus the other, the smaller the advantage of using a large confidence level– this makes sense since perfect prediction would imply no filter to switch. 3) distribution assumptions— this is a long and boring story for another day.
This method of probabilistic momentum has a lot of potential extensions and applications. It also requires some additional complexity to integrate into a multi-asset context. But it is conceptually and theoretically appealing, and preliminary testing shows that even in its raw form there is substantial added value especially when transaction costs are factored in.
Trackbacks
- Saturday links: all-in expenses | Abnormal Returns
- Probabilistic Momentum Spreadsheet | CSSA
- ETF Prophet | Probabilistic Momentum XL
- Probabilistic Momentum | Systematic Investor
- Probabilistic Momentum | Patient 2 Earn
- Probabilistic Absolute Momentum (PAM) | CSSA
- ETF Prophet | Probabilistic Absolute Momentum
- Somewhere else, part 123 | Freakonometrics
- Are Simple Momentum Strategies Too Dumb? Introducing Probabilistic Momentum | Supernova Capital
- Sistema Level | Carteras De Bolsa


Hi this is a really interesting filter option, I can see how this might be easy enough to code up in Matlab or R but what would the equivalent pseudo-code be for more of the programmatic trading tools using C# or similar.
I guess this is dependant on what that trading platform offers in terms of statistics or technical indicators but was interested to see how I could trial it out.
Hi Michael, you can code it using the specs from the excel sheet i will provide. Hopefully that helps as much as the pseudocode.
best
david
seems interesting and sure would like to kick the tires on this a bit.
any chance you can show the calculation in excel?
hi gerd, yes the excel sheet is on the way.
best
david
Hi David, I too would like to see a simple example in Excel if possible. Thanks.
Hi John, the excel sheet is on the way.
best
david
i would 3x that ….very interesting and worth the time to backtest….
hi GJK thanks.
best
david
Thanks for the interesting methodology. A couple clarification questions: (1) By tconf do you mean the cdf of the t-distribution? (2) By subtracting the tconf number from 1 when the IR is positive, don’t you constrain your result to 0-50% (assuming tconf is the cdf)? Seems like you would never get above that 60% threshold.
I tried implementing with a 63-day lookback using the cdf as my trigger point. My interpretation of your rules was that when the cdf > 60%, I entered long SPY and when the cdf was < 40% I entered long TLT. Otherwise, I just kept my previous trade. I did not get results nearly as smooth as yours, so I assume I misinterpreted somewhere.
Any insights as to where I went wrong would be great.
Thanks.
hi Rock, an excel sheet will be provided soon–not sure exactly what you are doing. I used the TDIST function in excel which varies between 0 and 1.
best
david
Using some quick back of the napkin math, I think a short-cut to getting to the same place is to just use the ratio of the stock prices and take use the (return / std. dev) of the ratio instead of the information ratio calculation. (Though, it requires that we are using using log-returns in all the computations and that the mean return is 0 in our std. dev calculation).
hi fire, that is true they are getting to the same place, though a shortcut would be to use the matrix calculation of portfolio variance for a large universe to compute tracking error from a computational standpoint.
best
david
brilliant idea
thanks Dave, i appreciate that.
best
david
What this strategy says to do is that when you are betting on horse 1 which is leading and then horse 2 jumps to the fore you should keep on betting on horse 1 until you are reasonably sure horse 2 is more likely to win.
So in general you will greatly reduce trading costs and you will slightly reduce your return. It’s like using a moving average to reduce trading costs. You will greatly reduce costs at a small costs of reduced return due to the lag in trading.
The fact that in the TLT, SPY example the return INCREASED is just luck.
hi Nick, your description is correct. However on the last point I agree and disagree with you—whether the specific example there is increased return doesn`t prove anything outside of that pair. However, where we disagree is that return CAN increase in the presence of mean-reverting elements at shorter frequencies that are either cross-sectional or asset specific this can indeed increase returns. This is also true if the insignificant frequencies contain white noise with a mean of zero–especially after transaction costs. Where moving averages and this method differ is in the use of smoothing—a threshold that is linked to predicted noise is superior and more flexible than a moving average.
best
david
I agree. For mean reverting situations lag in trading can help increase returns. ‘Twasn’t luck in the example.
Looking forward to the spreadsheet.
Inspiring work, David–an Excel model would both clarify the concept and deepen the conversation…
hi wray, thanks, an excel model is on the way…….
best
david
Thanks for this, David! Was wondering how many tails you’re using for the t-distribution?
hi Carlos, thanks it is a one-tailed test.
best
david
I think I replicated the results somewhat. Not sure which timeframe was used for the charts however I used this formula to calculate the Prob (A vs B): =IF(IRa<0,TDIST(ABS(IRa),Days-1,1),1-TDIST(IRa,Days – 1,1)). Where IRa is the annualised Information Ratio and Days is the lookback period. Then when this number hits 60%, go equity, and when the inverse hits 60%, go bonds. If the numbers are anywhere else then stay with the previous state. Does this sound right?
I can’t comment as to your other questions, but I’m wondering if you’re using the ABS function because the IR is a negative value? If this is the case, I found that if you use T.DIST.RT you don’t need to, and you also don’t need to specify tails — which David did not specify either. This is all a guess, of course, until we hear from the man himself!
hi Ken, I will be releasing a spreadsheet but this does sound right–thank you.
best
david
Hi David, Can I have a copy of the spreadsheet as well? Thanks a million, ling
David thats fantastic, looking forward to reading it, I’ve also posted a thread about converting it into a set of trading rules on http://www.tradersplace.net
As usual, a thoughtful and unique approach. You are way too creative with these algorithms. Many thanks for your contribution to my education. I look forward to seeing the Excel spreadsheet.
love this metaphor David, have enjoyed the lower trade frequency from using confidence factors though always need more live trades to compare the return impact.
have you considered this from a “both” standpoint vs. just an “either/or”? say these 2 horses are crushing the field, would it not be best to allocate resources into each of them, proportionately to their “lead”. once you introduce more assets, or a benchmark(say, the field), we no longer have to make binary decisions but have the luxury of incremental ones, right?
hi Derek, good to hear from you. thanks, glad you like the metaphor. there are a lot of ways to use this in concert with a broader universe. one way as you suggest is to proportionately allocated some fixed weight to each position based upon their ranking. another is to compute a matrix of pairwise indicators.
ultimately there are a lot of ways to use the information–including creating a continuous position size at even the pairwise level versus a binary allocation. i have considered a lot of different methods, and they each have benefits and disadvantages.
best
david
very interesting! thanks for sharing. few questions:
1. which function in excel you used for Tconf (IR)?
2. how did you calculate the tracking error?
3.so if i set a 3-month look back period (about 60days), the IR of current month is the last month Rp minus last month Ri divided by, a tracking error which is calculated from month(t-3) to month(t-1) ?
thanks!
hi David, not sure why my last comment did not show up in here…so i am posting again.
thanks for sharing this very interesting idea!
few questions:
1. which function did you use in excel to calculate the Tconf (IR)? is is the confidence of student T distribution?
2. i used monthly data and set lookback period = 3 months( about 60 trading days). so if i want calculate the IR of current month, i use (last month Rp minus last month Ri) divided by, a tracking error which is calculated from month(t-3) to month(t-1), right?
3. or is the Rp and Ri in your equation a momentum measure with a 60days lookback period?
thanks!
I tried to reproduce it in R but I don’t get the same performance. If I set the confidence level to 50% instead of 60%, the 2 curves match perfectly meaning that the 2 methods lead to the same result.
hi Patzoul, i tried to baktest as well. i got confused here: “This number for A vs B is subtracted from 1 if the information ratio is positive and kept as is if the information ratio is negative.” . so we have: if IR > 0 then 1-Tconf(IR), else what? the STD(which is the IR) in Tconf cannot be negative, is it if IR<0 then Tconf(IR) = IR? how did you code this? thanks!
For example, if Tconf(0.5) = 0.8 then I considered that I should have Tconf(-0.5) = 0.2 in other words that I should have Tconf(x) = 1 – Tconf(-x).
I’d like a copy of the spreadsheet as well. Thanks.
This is interesting, I’m curious how did you do the backtesting, excited to see your spreadsheet.
Now I’m going to try to implement it in R, hope it works. Thanks, David.
Here is my R code although it doesn’t give the same results.
nb.tickers = length(tickers)
data = new.env()
getSymbols(tickers,src=”yahoo”,from=”2009-12-30″,env=data,auto.assign=T)
i = 1
tmp = data[[tickers[i]]][,paste(tickers[i],”.Adjusted”,sep=””)]
for (i in 2:nb.tickers) {
tmp = cbind(tmp,data[[tickers[i]]][,paste(tickers[i],”.Adjusted”,sep=””)])
}
tmp = tmp[“2010-09-30::”,]
tmp = tmp[!is.na(rowSums(tmp)),]
tmp.perfs = ROC(tmp,type=”discrete”)
tmp.weights = tmp.perfs
tmp.weights[] = 0
tmp.weights.momentum = tmp.weights
colnames(tmp.weights) = paste(tickers,”.weights”,sep=””)
tmp.perfs.momentum = ROC(tmp,n=perf.days,type=”discrete”)
tmp.ir = tmp.perfs[,1]
tmp.ir[] = NA
colnames(tmp.ir) = “InformationRatio”
for (i in (perf.days+1):nrow(tmp.perfs)) {
tmp.ir[i] = InformationRatio(tmp.perfs[(i-perf.days+1):i,1],tmp.perfs[(i-perf.days+1):i,2])
if (tmp.perfs.momentum[i,1]>tmp.perfs.momentum[i,2]) {
tmp.weights.momentum[i,1] = 1
} else {
tmp.weights.momentum[i,2] = 1
}
}
tmp.proba = pt(tmp.ir,df=perf.days-1)
tmp.weights[tmp.proba>switch.threshold,1] = 1
tmp.weights[tmp.proba<(1-switch.threshold),2] = 1
tmp.weights = lag(tmp.weights,1)
tmp.weights[1,] = 0
tmp.weights.momentum = lag(tmp.weights.momentum,1)
tmp.weights.momentum[1,] = 0
write.table(cbind(tmp,tmp.weights),"~/Google Drive/R/Rotation.csv",sep=",",row.names=index(tmp),col.names=TRUE)
tmp.ret = ROC(tmp,type="discrete")
tmp.ret[1,] = 0
strat = xts(rowSums(tmp.ret*tmp.weights),order.by=index(tmp.ret))
strat = cumprod(1+strat)
colnames(strat) = "Strat"
I really enjoy reading your articles and postings and would also like to request a copy of the spreadsheet. Thanks!
Got a question, shouldn’t the T-stats be the active premium/(tracking error/sqrt(N)) ? Because it’s the standard error that should be in the denominator, not just the tracking error?
Good work, David.
Here are some questions I have:
In your formula the information ratio is satisfied within the first part–AVERAGE(C2:C61)/STDEV(C2:C61); what is then the function of the second part–*SQRT(COUNT(C2:C61))? Is this second component an attempt to mimic the one-sample form of the t-test, which looks like that t= (sample mean – critical/test mean)/ s *sqrt (n)?
Why going through the information ratio at all, and not instead building a more straightforward two sample t-test following the traditional formula t= (sample mean 1 – sample mean 2) / sqrt ( sample var 1/n1 + sample var 2/n2)?! Wouldn’t this produce a more genuine test?
Also regarding your instructions “This number for A vs B is subtracted from 1 if the information ratio is positive and kept as is if the information ratio is negative” is this already expressed in your formula IF(E7>0,1-TDIST(E7,COUNT(C2:C61),1),TDIST(-E7,COUNT(C2:C61),1)), or we need to further provide for it?
Finally, I followed your spreadsheet to test SPY vs TLT and I cannot quite replicate your results… Also it seems that such a system would drastically underperform holding the SPY through 2008–is this correct? There wasn’t any SPY buy-and-hold graph vs. the prob. strategy…
Thanks for sharing…
Hi everyone. I just came across this excellent post while looking for momentum related info. I am trading a rather crude rule based system on XIV/ZIV and I wanted to improve my switches between XIV, ZIV and cash.
Just to make sure I understand correctly: David uses the 60 day rolling returns to evaluate the probability of the persistence of the trend (A perf > B perf and vice versa). Am I right?
Are the returns used : daily log returns or raw?
Can this approach be replicated so as to use more than 2 assets? (any pointer would be nice 🙂 )
David: Would it be possible for you to share the spreadsheet used to come up with the charts and difference in number of trades as shown in the post?
Thanks!
The results look impressive, but I’ve seen all to many similar strategies that did also, but did not stand up to a thorough investigation of the back testing methodology. Also the 25, 30, 35 day results fluctuation are a cause for concern.
Are the back tests explained? Did I miss them?
Just curious if this is extendable to more than two asset classes within a multi asset rotation framework. Thanks